
About
A web app where a user can train a pasta identification model using hand-drawn pictures and test the model on new drawings. We used a convolutional neural network and created our project using Python, Keras (an API from Tensorflow) and Flask.
Tools
-
Python
-
Tensorflow
-
HTML/CSS/Javascript
Members
-
Spoorthi Cherivirala
-
Ricky Lee



Demo Video
Walkthrough:
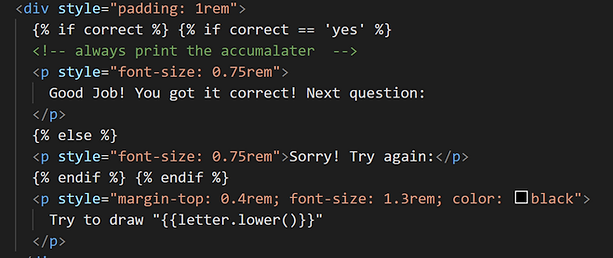
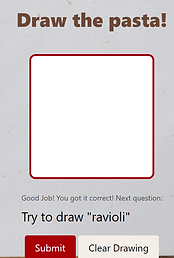
The user first enters the game screen; the displayed interface has 2 options: either play or train the model. So we’re gonna start with training the model. This model has already been trained with 200 pasta drawings, so right now we're just adding to this dataset. At any point, the user can clear their drawing and start over. After they are done, the user can return to the home screen and choose to play the game. Given a pasta prompt, they must draw the corresponding pasta shape. If their drawing is detected as correct, the game will display a positive message, if not, it displays a negative message and allows the user to progress to the next question.
1- Web App Structure
Routes
The home page links to a page to add user-inputted data (hand-drawn) to the model, as well as a page to test the model against user-inputted data. Each of these pages is an API endpoint from the main home page (with a corresponding route), and has their own GET and POST methods for collecting image data and outputting prompts respectively.
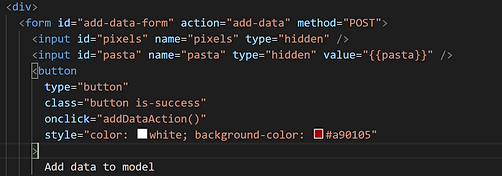
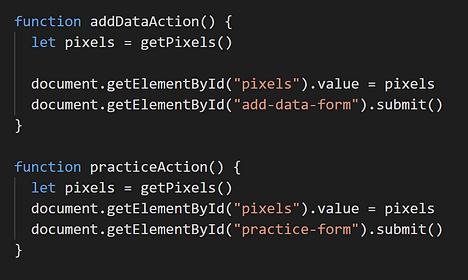
On the page to add data, the user is prompted by a short message asking for a drawing representing a certain pasta. This drawing is created in a small canvas by clicking and dragging. When the user is done, they can click complete to submit the form in the web app which then passes the image data to the model. Of course, there is the option to clear the canvas and start over.
The page to test the model has a similar layout. However, instead of submitting an image as training data for the model, the model classifies the image and provides feedback on whether it believes the image to be correct or not.
1.5- Styling (HTML/CSS)
Play & Add to Model Pages

Index & Main CSS Stylesheet

2- Getting User Input (Javascript)
Javascript for mouse input on canvas
We use event listeners, which wait for user inputs on the mouse for the canvas. We altered the weight, color, and responsiveness of the cursor. The image on the right depicts the resulting canvas on the draw page.



3- Representation of User Input

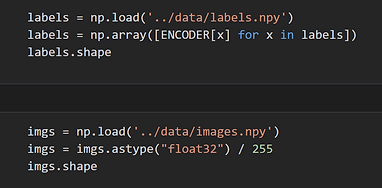
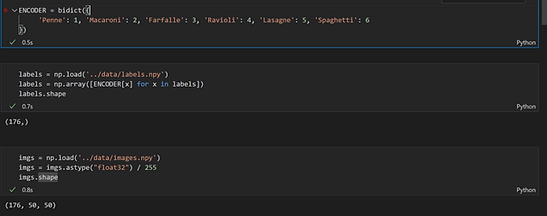
Hand-drawn user input represented as a compressed array of 0s and 1s
We used the Canvas API, and the function getImageData. We downsample the image data that is taken from the hand-drawn input of the pasta to go from a 200x200 image to 50x50.
4- Collecting data from user
When a user is done drawing, they submit through a Javascript form which also has a label for their drawing.
The bi-directional encoder array represents a dictionary of our types of pasta with their corresponding string name. This is important for randomly selecting a pasta for the user to draw (whether for adding data or for testing new drawings).
We collect the data into a npy file, which persistently stores a NumPy array on local disk. This ensures that a user can still run the web app without training a new model if they trained one in a previous session.
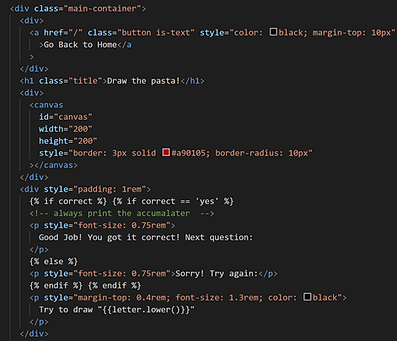
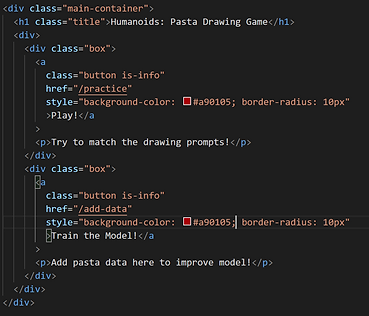
We wanted to make our game appear appealing and pasta-themed! This is our custom CSS/ HTML to insert a pasta background and include a consistent theme of red buttons and styling for clear/ submit, etc. The image on the left shows the canvas element dimensions and specifications as well as the messages that will display depending on correctness. The styling for the play and add to model pages are very similar and most include in-line CSS.
The styling for our main page comes from our CSS stylesheet where we dictate basic font sizes, styles, margins, etc for the different hierarchy headers as well as boxes on the page. The HTML shows the two-button text to either play or add to model with in-line CSS.


4.5- Pairing Data with label
Each drawing is paired with a label, which is taken from the aforementioned encoder array.


5- Aggregating data by labels
User data inputted into array “imgs”, paired with labels from bi-directional array “ENCODER”
Data then split into training and test setsE
Each drawing, as an array of pixel values, is then paired with its label, and is then stored in a larger array containing all the images for each label (ie. all the lasagna drawings are grouped together this way).
Once the data has been collected and the model begins training, it is important to split the data into training and test sets. This ensures that different data is being used to train and test the model. We randomly sample the data when splitting.

6- Model
We use a convolutional neural network, which is used for analyzing images
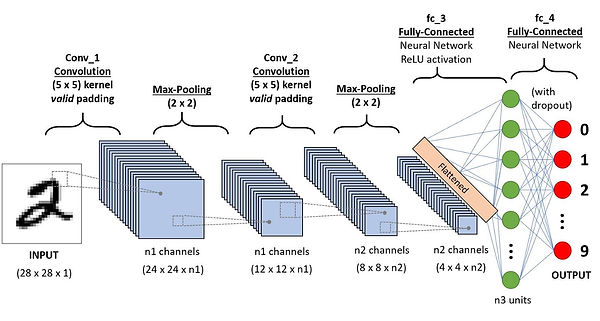
Like neural networks, they are comprised of layers and try to analyze some type of input data
-
CNNs are generally used for image processing and analysis
Convolving - sliding window of pixels which does some type of operation with a certain filter, which is just a matrix of values
-
Ie. element wise multiplication used for c
-
CNNs are made of convolutional layers
-
Convolutional layers are made of filters
-
Filters are used to find patterns in an image - simple ones can be used for edge detection, whereas more complex ones can be used later on to identify perhaps corners, circles, or even real objects (in images)
-
Each layer tends to have more and more filters, as it picks up on patterns in the image
-
Code Notes (building the model)
Code Notes (training the model)

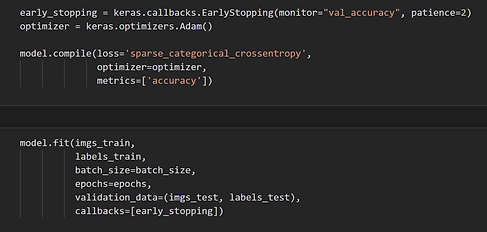
-
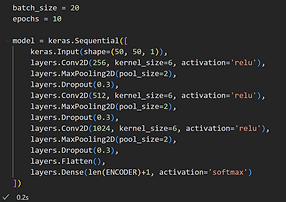
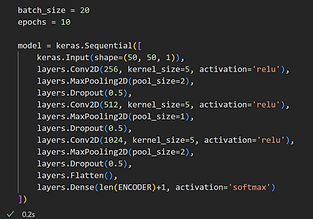
We use a convolutional neural network, which is used for analyzing images. Our model uses three layers, using the relu activation function. We utilize max pooling, which takes the strongest / highest value in a window of 2 by 2 pixels. We also use dropout, which downsamples the data. Both of these methods reduce the amount of data being processed, while retaining the most significant data for the model. Each layer reduces the amount of data by more than a factor of ten.
-
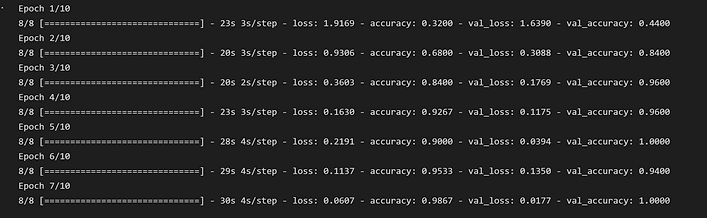
To obtain a metric for optimization in the model, we use the sparse categorical cross-entropy loss function. This is due to the multi-class nature of our classification problem, as well as the fact that each image can only be one pasta (there are no hybrid pasta drawings allowed). We use the Adam optimizer, as is standard practice with this type of image classification problem. Finally we use an early stopping function which ends the training process if two epochs pass without progress in the performance metric, accuracy.
6.5- Training Model
Added 197 data points, Model took 5m 17s to run (20 epochs)
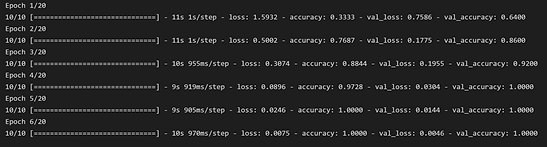

6.5- Experimenting with model
Batch size, epochs, kernel size
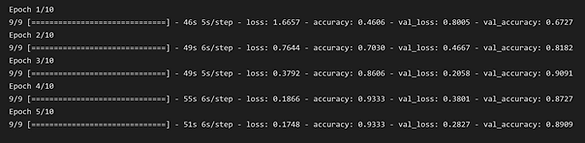
In order to improve accuracy, we experimented with changing the specifications of the model including batch size, epochs, and kernel size. Below are some of the results our models generated. As you can see in the bottom left image, the validation and training accuracy are similar which is good. There isn’t too much overfitting.

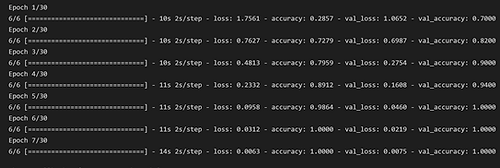

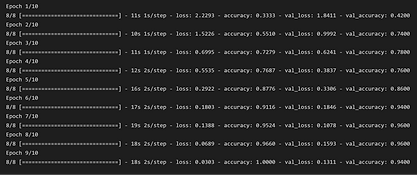
7- Showing Results
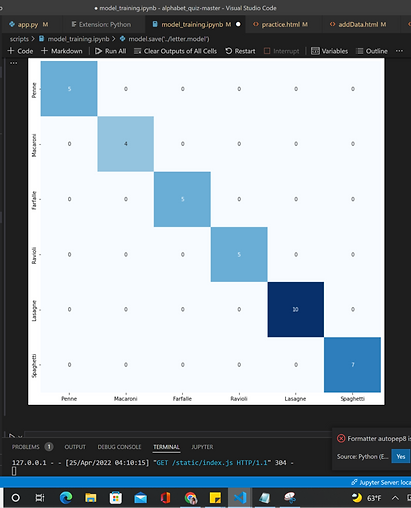
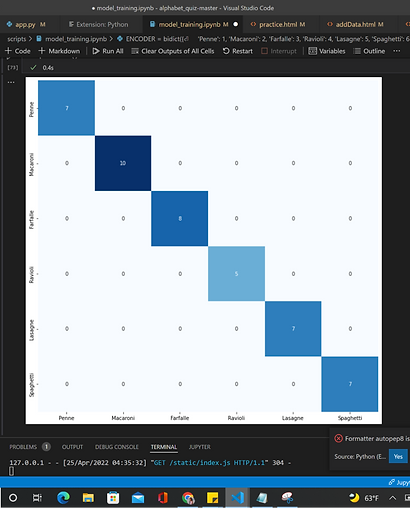
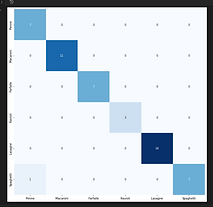
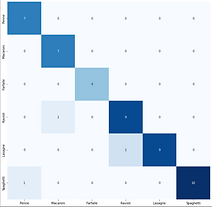
Confusion matrix to show incorrect vs. correct guesses
This confusion matrix shows incorrect vs. correct guesses made by our final model. There are no incorrect guesses, suggesting that the data might be too homogenous or the problem may be too simple (we may need more pasta shapes or more complex ones). In previous iterations of the model, there were often mistakes made in terms of distinguishing between ravioli and penne. This makes sense considering the similarities in their shapes. When the model was initially generated with few data entries, ravioli and lasagne were often mistaken because of their essential rectangle shape.
8- "Play" Page
Play page allows user to test their drawings once the model has been generated
Determines correctness, passes it the html code
The right images show the corresponding html/css pages depending on the correctness of the user input. Play page allows the user to test their drawings once the model has been generated. Using the POST method for this page a randomly generated label is chosen and outputted through a prompt on the screen. The GET method collects the user’s drawing and runs the model on it. On submit the model’s label and the prompted label are compared, which is how correctness is determined.

9- Next Steps
Based on feedback from in-class presentations, moving forward we worked on developing these steps.

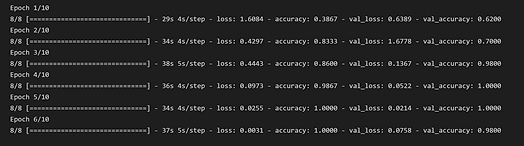
Improving Model: We experimented and analyzed results from running different models when changing epochs, batch-size, max pooling, dropout size, and kernel-size; We also generated new heatmaps that show increased confusion during certain models with more downsampling.
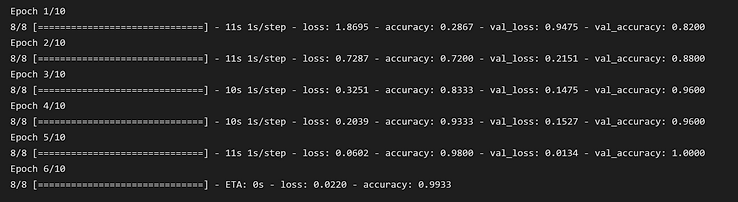

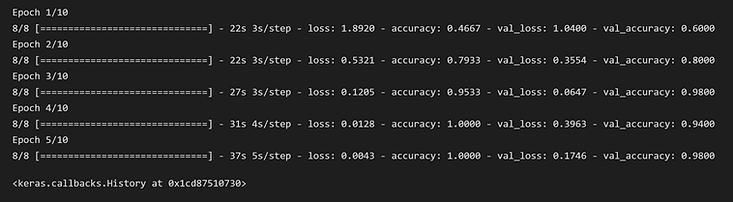



Complex Pasta: We tried to train the model on new drawing styles to increase its versatility (imitating different users) and see if it's still able to distinguish between pasta shapes effectively when playing the game. We simplified the pasta shapes into one line (squiggle, rectangle, square, triangle) to emulate how others might draw them as well as drew the pasta in different orientations. Image below shows some of these entries.
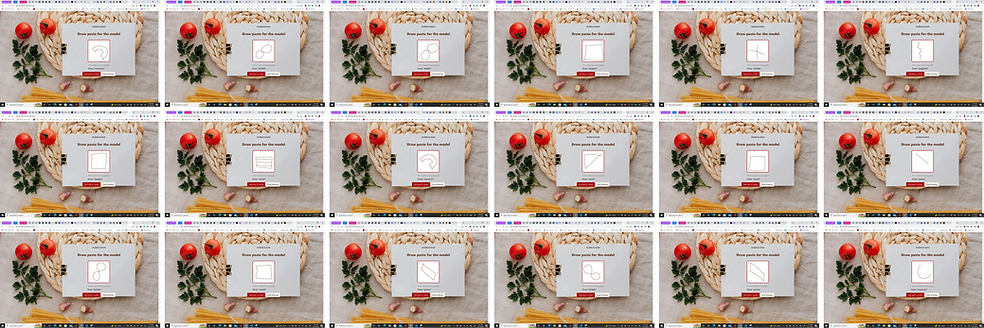.png)

After training the model with around 100 of these abnormal pasta shapes, the accuracy decreased when we ran the same model. The heatmap also showed a lot more confusion between the pasta shapes, especially ravioli and lasagne which is what we predicted because of the similarities in their appearance. Although most of the shapes are still distinguishable, this indicates that our game would be more ideal when the model is trained by the actual players.
Findings and Reflections
Most of our data was created by one person (Spoorthi) - this may have contributed to the ease with which the model classified data. Pastas drawn in different styles, using different stroke orders, by different people, may complicate the classification problem.
Each image contains a lot of data, but the model did not take very long in terms of processing these volumes of data. We believe that the max pooling and dropout downsampling techniques greatly contributed to this - it was impossible to run the model without doing this.
If the stroke order or way in which the pasta was drawn is encoded into the model, it may be possible for it to identify users given an image and the correct label for which it represents. This would be a very difficult task considering the limits of convolutional neural networks but perhaps with enough training data and time it would be able to solve this. This would be an interesting future addition to this project.
Finally, in the near future we will gamify the web app, as to show data to the user in terms of their performance relative to the model over time.